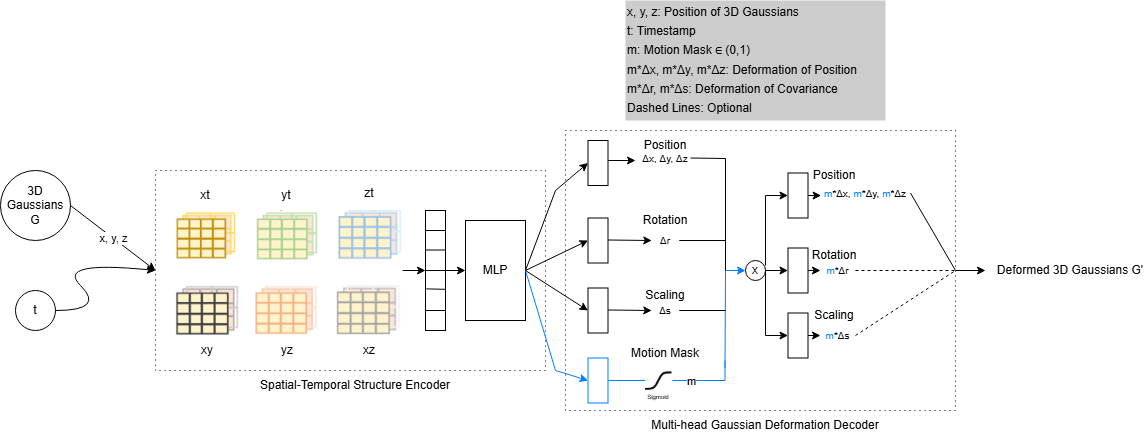
4D Gaussian Splatting (4DGS) models dynamic scenes by coupling canonical Gaussians with a time-dependent deformation network — but applies deformation uniformly to every Gaussian, including those representing static regions.
In real scenes, only a small fraction is dynamic. Treating all Gaussians identically wastes representational capacity and prevents identifying which parts of the scene are actually moving.
Our solution: a lightweight motion-mask head that predicts a per-Gaussian soft gate mi(t) ∈ (0,1), controlling how much each Gaussian deforms — learned fully without supervision.
Abstract
This project studies motion-aware dynamic scene reconstruction built on top of the 4D Gaussian Splatting (4DGS) framework. The system takes a set of images with associated camera poses and timestamps as input and outputs a 4D Gaussian representation enabling novel-view rendering over time. While the baseline 4DGS model represents dynamic scenes by predicting time-dependent deformations for all Gaussian primitives in a canonical space, it lacks an explicit mechanism to distinguish between static and moving elements.
To address this, we introduce a lightweight motion-mask branch within the 4DGS deformation network. This mask acts as a learned scalar gate that modulates deformation strength and is optimized jointly with image reconstruction. Our method is fully unsupervised: it requires no ground-truth motion labels or external segmentation. Instead, it guides the learning process through a combination of the standard reconstruction objective and two novel regularizers: a binarization loss and a static-deformation loss.
Experiments on D-NeRF scenes show that the proposed
method can modestly improve reconstruction on strongly dynamic
synthetic scenes, with up to +0.28 dB PSNR on BOUNCINGBALLS
and +0.22 dB on JUMPINGJACKS. However, the method does
not produce universal reconstruction gains: on the real-world
HyperNeRF CHICKCHICKEN scene, baseline 4DGS remains
slightly better on the main image metrics. The results also
show that reconstruction quality and motion-mask separability
are related but not identical objectives. A near-binary mask is
not always required for better reconstruction, while stronger
regularization can improve mask diagnostics without improving
image quality.
Method
In the standard 4DGS pipeline, deformation offsets (Δμi, Δsi, Δri) are applied to every Gaussian regardless of whether the corresponding region actually moves. We address this by adding a single linear layer gφ that maps the shared deformation hidden state hi(t) to a scalar pre-activation and applies a sigmoid:
mi(t) = σ(gφ(hi(t))) ∈ (0, 1)
The mask gates the positional update: μi(t) = μ0i + mi(t) · Δμi(t). When --motion-gate-rot-scale is enabled, scale and rotation are gated analogously. Opacity is intentionally left ungated, as it is managed by the 3DGS densification and pruning logic.
Because the mask is predicted from the shared feature rather than stored as a persistent per-Gaussian parameter, it requires no modification to Gaussian cloning, pruning, optimizer-state management, or checkpoint serialization — it is a drop-in addition of a single MLP head.
Architecture: Motion Mask Integration
The motion mask head is appended to the deformation decoder. The shared hidden feature feeds four heads:
position, rotation, scale, and motion mask.
Motion-Mask Forward Path (scene/deformation.py)
1Start from canonical Gaussian attributes: position, scale, rotation, opacity, SH color.
2Query HexPlane field at canonical position and timestamp → spatiotemporal feature F_i(t).
6Rasterize deformed Gaussians and compute image reconstruction loss.
Training Objective
The full training loss adds two motion-specific regularizers on top of the baseline 4DGS objective:
ℒ = ℒimg + λgridℒgrid + λbinℒbin + λstaticℒstatic
Binarization Loss
ℒ_bin = (1/N) Σ m_i(t)(1 − m_i(t))
Minimized when each mask value is at 0 or 1. Encourages a cleaner binary static/dynamic assignment.
Static-Deformation Loss
ℒ_static = (1/N) Σ (1 − m_i(t)) ‖Δμ_i(t)‖²
Penalizes large positional deformations for Gaussians the mask identifies as static (mi ≈ 0).
Discarded prototype: An earlier sparsity-only prototype used a penalty ℒsparse = (1/N) Σ mi(t) that drove all masks toward zero (all-static collapse) and was discarded. It is not part of the final method.
Identifiability Limitation
The motion-mask formulation introduces an inherent ambiguity. The renderer does not observe the mask and deformation independently, but only their product:
mi(t) · Δμi(t)
As a result, multiple configurations can produce similar rendered images. For example, a small mask with a large deformation can be equivalent to a large mask with a small deformation. This creates an identifiability issue: image reconstruction alone cannot uniquely determine whether motion should be attributed to the mask or to the deformation magnitude.
The binarization and static-deformation losses are introduced to partially resolve this ambiguity by encouraging the mask to take on interpretable values and discouraging deformation in low-mask regions. However, this ambiguity is not fully eliminated and contributes to the observed gap between reconstruction quality and mask separability.
Notation Reference
Symbol
Meaning
Code variable
μ⁰ᵢ
Canonical Gaussian center
pc.get_xyz / rays_pts_emb[:,:3]
Δμᵢ(t)
Predicted positional deformation
dx
Fᵢ(t)
HexPlane spatiotemporal feature
grid_feature
hᵢ(t)
Shared hidden feature after projection
hidden
mᵢ(t)
Learned motion mask ∈ [0,1]
motion_mask
λ_bin
Binarization loss weight
motion_bin_lambda
λ_static
Static-deformation loss weight
static_deform_lambda
Diagnostics & Tooling
Since the system operates without ground-truth motion masks, we implemented a suite of diagnostic tools to monitor the emergence of static-dynamic separation. The training pipeline logs per-iteration mask statistics to motion_mask_stats.jsonl, tracking variables such as:
Mean & Std Dev: Overall distribution of the learned gate values.
Dynamic Fraction: The percentage of the scene identified as moving, specifically the fraction where m > 0.4.
Loss Components: Real-time values for the static-deformation and binarization regularizers.
To analyze spatial behavior, the method exports specialized color-coded PLY point clouds. In these files, the RGB channels are mapped to mask intensity: Red indicates high motion-mask values (predicted dynamic regions), while Blue indicates low values (predicted static regions).
Results
We evaluated our method across two synthetic D-NeRF scenes (BouncingBalls, JumpingJacks) and one real-world HyperNeRF scene (ChickChicken). Our findings indicate that while motion-aware gating improves metrics in controlled synthetic environments, real-world data presents unique challenges for unsupervised decomposition.
Reg-C: λ_static = 2e-3, λ_bin = 2e-3 — stronger on both
Over-reg: λ_static = 1e-2 — collapse sanity check
Baseline vs. Reg-B Comparison
BouncingBalls (Baseline)
BouncingBalls (Reg-B)
JumpingJacks (Baseline)
JumpingJacks (Reg-B)
ChickChicken (Baseline)
ChickChicken (Reg-B)
D-NeRF strongly dynamic synthetic scene. All three stable regularized variants improve over baseline. Reg-B achieves the highest PSNR (+0.28 dB); Reg-C achieves the best SSIM and LPIPS scores.
Method
PSNR ↑
SSIM ↑
LPIPS-VGG ↓
LPIPS-Alex ↓
MS-SSIM ↑
Baseline 4DGS
40.68
0.9943
0.01536
0.00603
0.99540
Reg-A (λ_s=1e-3, λ_b=1e-3)
40.87
0.9945
0.01438
0.00563
0.99558
Reg-B (λ_s=2e-3, λ_b=1e-3)
40.96
0.9945
0.01442
0.00523
0.99562
Reg-C (λ_s=2e-3, λ_b=2e-3)
40.90
0.9947
0.01362
0.00509
0.99568
Over-reg (λ_s=1e-2, λ_b=1e-3)
40.72
0.9943
0.01559
0.00597
0.99531
Reg-B shows the clearest static/dynamic separation (highest dynamic fraction and mask spread). Reg-C, despite its better reconstruction scores, produces a more conservative and compressed mask — illustrating the reconstruction–separability tradeoff.
Motion-Mask Diagnostics (end of training)
Method
Mean m
Std m
Dyn. frac.
Frac. m>0.4
Early prototype (no reg.)
0.248
0.064
0.000
—
Reg-A
0.185
0.190
0.012
0.216
Reg-B
0.218
0.249
0.260
0.388
Reg-C
0.140
0.214
0.049
0.262
Over-reg
0.999
0.002
1.000
1.000
Method
PSNR ↑
SSIM ↑
LPIPS-VGG ↓
LPIPS-Alex ↓
MS-SSIM ↑
Baseline 4DGS
35.40
0.9856
0.01995
0.01266
0.99362
Reg-A (λ_s=1e-3, λ_b=1e-3)
35.58
0.9864
0.01897
0.01233
0.99401
Reg-B (λ_s=2e-3, λ_b=1e-3)
35.62
0.9864
0.01895
0.01262
0.99400
Reg-C (λ_s=2e-3, λ_b=2e-3)
35.40
0.9859
0.01988
0.01314
0.99364
Best per column in bold blue. Reg-C returns to near-baseline quality on JumpingJacks, confirming that optimal regularization weights are scene-dependent.
Real-world dynamic scene from HyperNeRF (CHICKCHICKEN). Unlike the synthetic D-NeRF scenes, the proposed method does not consistently improve reconstruction quality. The baseline 4DGS remains slightly better on most primary image metrics, highlighting a gap between synthetic and real-world behavior.
Method
PSNR ↑
SSIM ↑
LPIPS-VGG ↓
LPIPS-Alex ↓
MS-SSIM ↑
Baseline 4DGS
26.92
0.7969
0.3369
0.1854
0.9107
Reg-A
26.87
0.7968
0.3422
0.1862
0.9111
Reg-B
26.91
0.7967
0.3440
0.1903
0.9107
The proposed method does not improve PSNR or LPIPS on this real-world scene. However, mask diagnostics still show stronger static–dynamic separation under higher regularization.
Motion Mask Visualizations
Red/blue PLY exports: red = high mask (dynamic), blue = low mask (static).
Scene: BouncingBalls
Reg-A: λs=1e-3, λb=1e-3
Reg-B: λs=2e-3, λb=1e-3
Reg-C: λs=2e-3, λb=2e-3
Scene: JumpingJacks
Reg-A: λs=1e-3, λb=1e-3
Reg-B: λs=2e-3, λb=1e-3
Reg-C: λs=2e-3, λb=2e-3
Key Findings & Analysis
Our experiments reveal a nuanced relationship between motion-aware regularization and reconstruction fidelity. While the gated mask provides an interpretable diagnostic of scene dynamics, "cleaner" masks do not always translate to higher PSNR.
Quantitative Performance
Scene
Metric
Baseline 4DGS
Ours (Reg-B)
Delta
BOUNCINGBALLS
PSNR (dB) ↑
40.67
40.96
+0.28
JUMPINGJACKS
PSNR (dB) ↑
35.40
35.62
+0.22
CHICKCHICKEN
PSNR (dB) ↑
26.92
26.91
-0.01
1. Dynamic Scene Gains
On synthetic scenes with high-velocity motion (D-NeRF), the motion mask successfully isolates moving primitives, providing modest reconstruction gains by preventing "motion bleed" into static areas.
2. The Real-World Challenge
In real-world captures like ChickChicken, baseline 4DGS remains slightly superior. Complex lighting and capture artifacts can cause the unsupervised mask to misidentify noise as motion, leading to slight PSNR drops.
3. Quality vs. Separability
We found that reconstruction quality and mask separability are distinct objectives. A perfectly binary (Red/Blue) mask isn't always required for the best visual output; often, a "soft" gate yields better gradients for optimization.
Conclusion: Unsupervised static-dynamic separation remains an underconstrained problem when supervised solely by image reconstruction. However, our gated approach provides a viable, lightweight path toward more interpretable 4D representations.
SDD-4DGS — Most closely related work; proposes static–dynamic decoupling for 4DGS by assigning a persistent dynamic perception coefficient to each Gaussian. Our approach predicts the coefficient from the shared deformation feature at each forward pass, avoiding modifications to Gaussian cloning, pruning, or optimizer-state logic.
@article{ren2025motionaware4dgs,
author = {Ren, Yuan and Taylor, Ben and Swierad, Lucas},
title = {Motion-Aware Regularization via Soft Mask Gating for 4D Gaussian Splatting},
year = {2026},
note = {ROB 430 Final Project, University of Michigan},
url = {https://github.com/yuanren114514/ROB_430_Final_Project},
}